










مقدمهای بر بیوانفورماتیک
بیوانفورماتیک بهطور کلی به استفاده از روشهای محاسباتی و الگوریتمها برای تحلیل دادههای زیستی گفته میشود. این رشتهی علمی میانرشتهای در واقع ترکیبی از زیستشناسی، ریاضیات، فیزیک، و علوم کامپیوتر است که هدف آن تحلیل و تفسیر دادههای زیستی با استفاده از ابزارهای محاسباتی است. بیوانفورماتیک از طریق پردازش دادهها، جستجوی توالیهای ژنوم، پیشبینی ساختارهای پروتئینی، و تجزیه و تحلیل دادههای متابولیک، اطلاعات با ارزشی در زمینههای مختلف پزشکی، کشاورزی، و داروسازی فراهم میآورد.
این حوزه در دهههای اخیر تحولی عظیم در زیستشناسی و پزشکی ایجاد کرده است. بهعنوان مثال، تسلسلیابی ژنوم انسان (Human Genome Project) که در اوایل دهه 2000 به پایان رسید، بسیاری از پرسشهای زیستشناسی را با استفاده از ابزارهای بیوانفورماتیکی پاسخ داد و به پزشکان و دانشمندان کمک کرد تا راههایی جدید برای درمان بیماریها پیدا کنند.
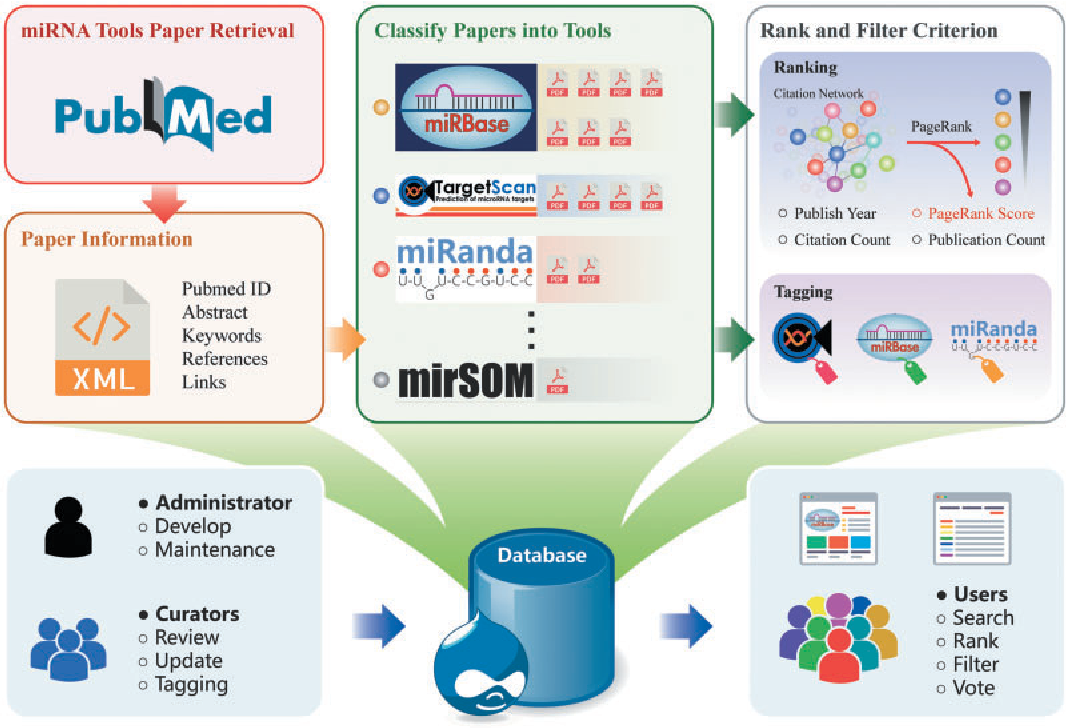
کاربردهای بیوانفورماتیک:
- زیستشناسی مولکولی: تجزیه و تحلیل دادههای مربوط به DNA، RNA و پروتئینها.
- پزشکی و داروسازی: استفاده از اطلاعات ژنومی برای درمانهای شخصی و کشف داروهای جدید.
- کشاورزی: بهبود عملکرد گیاهان و حیوانات از طریق مطالعه ژنها.
- ایمنی زیستی: شبیهسازیهای مولکولی برای پیشبینی رفتار مواد و داروها در بدن.
پایگاههای داده بیولوژیکی: مفاهیم و اهمیت

پایگاههای داده بیولوژیکی مجموعهای از اطلاعات زیستی هستند که بهصورت دیجیتالی ذخیره و مدیریت میشوند و در اختیار محققان و دانشمندان قرار میگیرند. این پایگاهها ابزارهایی برای دسترسی سریع به اطلاعات ژنومی، پروتئینی، متابولیک و سایر دادههای زیستی هستند. بدون این پایگاههای داده، انجام تحقیقات بیولوژیکی پیچیده و بهروزرسانیهای مداوم در این حوزه تقریباً غیرممکن بود.
اهمیت پایگاههای داده:
- ذخیرهسازی و دسترسی سریع به دادهها: پایگاههای داده بیولوژیکی به دانشمندان این امکان را میدهند که به راحتی دادهها را جستجو و مقایسه کنند.
- تجزیه و تحلیل مقایسهای: استفاده از پایگاههای داده برای مقایسه دادههای ژنومی یا پروتئینی از گونههای مختلف.
- پیشبینی ساختار و عملکرد پروتئینها: بسیاری از پایگاههای داده شامل اطلاعات ساختاری پروتئینها و تعاملات مولکولی هستند.
انواع پایگاههای داده بیولوژیکی
پایگاههای داده بیولوژیکی را میتوان به دستههای مختلفی تقسیم کرد. این دستهها شامل پایگاههای داده توالیهای ژنی، پروتئینی، ساختار پروتئینها، متابولومیک، و ژنومیک مقایسهای هستند. هرکدام از این پایگاهها هدف خاص خود را دارند و برای نیازهای متفاوت در بیوانفورماتیک طراحی شدهاند.
پایگاههای داده توالیهای ژنی و پروتئینی
این دسته از پایگاههای داده شامل توالیهای DNA و پروتئینها از گونههای مختلف است که محققان میتوانند از آنها برای شناسایی توالیها، تجزیه و تحلیل تفاوتهای ژنتیکی، یا پیشبینی عملکردهای ژنها استفاده کنند.
- GenBank: پایگاه داده مشهور و عمومی که بهطور عمده توالیهای ژنومی و پروتئینی را ذخیره میکند. این پایگاه توسط مؤسسه ملی بهداشت آمریکا (NIH) پشتیبانی میشود و یکی از بزرگترین منابع اطلاعات ژنومی در جهان است.
- UniProt: پایگاه دادهای است که اطلاعات دقیق و کامل درباره پروتئینها و توالیهای آنها را فراهم میکند. این پایگاه داده شامل اطلاعاتی در مورد عملکرد، ساختار، و تعاملات پروتئینی است.
- EMBL و DDBJ: این دو پایگاه داده به ترتیب در اروپا و ژاپن تأسیس شدهاند و بهطور عمده به ذخیرهسازی توالیهای DNA میپردازند.
پایگاههای داده ساختار پروتئین
این پایگاهها اطلاعات مربوط به ساختارهای سهبعدی پروتئینها را ذخیره میکنند که بهطور گسترده در پیشبینی عملکرد و مطالعه تعاملات مولکولی استفاده میشود.
- PDB (Protein Data Bank): یکی از مشهورترین پایگاههای داده برای ذخیرهسازی ساختارهای سهبعدی پروتئینهاست. این پایگاه شامل اطلاعاتی از پروتئینهای حلشده توسط روشهایی نظیر اشعه ایکس و کرایوالکترون میکروسکوپی است.
پایگاههای داده مسیرهای زیستی
این پایگاهها مسیرهای شیمیایی و بیولوژیکی را در داخل سلولها مدل میکنند. آنها اطلاعاتی درباره واکنشهای آنزیمی، مسیرهای سیگنالینگ، و فرآیندهای متابولیکی فراهم میکنند.
- KEGG (Kyoto Encyclopedia of Genes and Genomes): یکی از شناختهشدهترین پایگاههای داده برای مطالعه مسیرهای ژنومی، بیوشیمیایی، و دارویی است.
- Reactome: پایگاه دادهای است که اطلاعاتی درباره مسیرهای بیولوژیکی در انسان و سایر موجودات را ذخیره میکند.
پایگاههای داده متابولومیک
این پایگاهها شامل دادههای متابولیکی هستند که بهطور عمده در مطالعه و تجزیه و تحلیل متابولومها و مواد شیمیایی تولید شده توسط سلولها و بافتها استفاده میشوند.
- HMDB (Human Metabolome Database): پایگاه دادهای است که اطلاعاتی در مورد متابولیتهای انسانی، خصوصیات آنها، و مسیرهای متابولیک موجود در بدن فراهم میکند.
پایگاههای داده ژنومهای مقایسهای
این دسته از پایگاهها به مقایسه ژنومهای مختلف موجودات زنده میپردازند و به محققان امکان میدهند که تفاوتها و شباهتها را در سطح ژنوم مقایسه کنند.
- Ensembl: پایگاه دادهای است که ژنومهای مختلف گونههای حیوانی و گیاهی را مقایسه میکند.
- UCSC Genome Browser: ابزار کاربردی برای مشاهده و مقایسه دادههای ژنومیک، که اطلاعات گستردهای در مورد توالیهای ژنومی فراهم میکند.
روشها و الگوریتمهای بیوانفورماتیک
الگوریتمهای بیوانفورماتیک ابزارهای محاسباتی هستند که برای تجزیه و تحلیل دادههای بیولوژیکی استفاده میشوند. این الگوریتمها میتوانند شامل جستجو، تطابق، پیشبینی ساختار، و شبیهسازیهای پیچیده باشند. از جمله مهمترین الگوریتمها میتوان به موارد زیر اشاره کرد:
- BLAST (Basic Local Alignment Search Tool): یکی از معروفترین الگوریتمها برای جستجو و مقایسه توالیهای DNA و پروتئینها است. این ابزار به محققان کمک میکند تا شباهتها و تفاوتهای موجود در دادههای ژنومی را شبیهسازی کنند.
- HMMER: این ابزار برای جستجوی توالیهای پروتئینی و DNA با استفاده از مدلهای مارکوف بهکار میرود و دقت بالایی در پیشبینی ساختارها و تعاملات دارد.
- فراخوانی ساختار پروتئین: الگوریتمهایی همچون Rosetta و MODELLER که برای پیشبینی ساختارهای سهبعدی پروتئینها استفاده میشوند.
چالشها و مشکلات موجود در بیوانفورماتیک
بیوانفورماتیک بهطور کلی با چالشهای زیادی روبهرو است. برخی از این چالشها عبارتند از:
- حجم عظیم دادهها: در دنیای امروز، حجم دادههای بیولوژیکی به حدی بزرگ است که پردازش و ذخیرهسازی آنها به چالشهای فنی جدی تبدیل شده است.
- خطاهای دادهای: دادههای زیستی معمولاً شامل خطاها و نویزهایی هستند که باید اصلاح شوند.
- چالشهای تجزیه و تحلیل: پیچیدگی در تحلیل دادههای پیچیده و نیاز به الگوریتمهای پیچیدهتر، از دیگر مشکلات عمده است.
آینده بیوانفورماتیک و پایگاههای داده مرتبط
بیوانفورماتیک در آینده نزدیک با پیشرفتهای عمدهای روبهرو خواهد بود. یکی از زمینههایی که در حال حاضر در حال رشد است، استفاده از یادگیری ماشین و هوش مصنوعی برای تحلیل بهتر دادههای بیولوژیکی است. در کنار این، پایگاههای داده بیولوژیکی نیز روز به روز بهروزتر و جامعتر میشوند، بهطوری که اکنون دسترسی به اطلاعات در سطوح مختلف و با دقت بالا امکانپذیر است.
نتیجهگیری
بیوانفورماتیک و پایگاههای داده مرتبط با آن یکی از ابزارهای اصلی در پیشرفتهای علمی و پزشکی هستند. این حوزه با ترکیب علم زیستشناسی و تکنولوژیهای محاسباتی، راههای جدیدی برای تحقیق و توسعه ارائه میدهد. بهبود و گسترش پایگاههای داده بیولوژیکی و استفاده از روشهای نوین تحلیل دادهها میتواند به پیشرفتهای چشمگیری در کشف درمانهای جدید، بهبود کیفیت زندگی و پیشرفتهای پزشکی کمک کند.


دیدگاهتان را بنویسید